4.0 KiB
Miscellaneous Topics
In this section, we discuss other miscellaneous and uncategorized topics in prompt engineering. It includes relatively new ideas and approaches that will eventually be moved into the main guides as they become more widely adopted. This section of the guide is also useful to keep up with the latest research papers on prompt engineering.
Note that this section is under heavy construction.
Topic: - Active Prompt - Directional Stimulus Prompting - Program-Aided Language Models - ReAct - Multimodal CoT Prompting - GraphPrompts
Active-Prompt
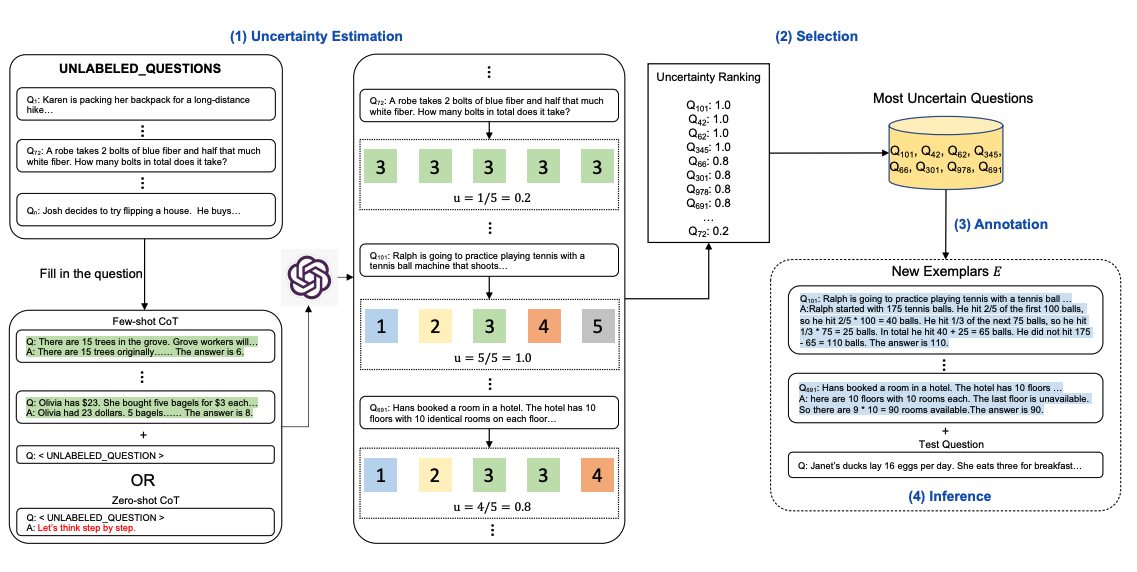
Chain-of-thought (CoT) methods rely on a fixed set of human-annotated exemplars. The problem with this is that the exemplars might not be the most effective examples for the different tasks. To address this, Diao et al., (2023) recently proposed a new prompting approach called Active-Prompt to adapt LLMs to different task-specific example prompts (annotated with human-designed CoT reasoning).
Below is an illustration of the approach. The first step is to query the LLM with or without a few CoT examples. k possible answers are generated for a set of training questions. An uncertainty metric is calculated based on the k answers (disagreement used). The most uncertain questions are selected for annotation by humans. The new annotated exemplars are then used to infer each question.
Program-Aided Language Models
Gao et al., (2022) presents a method that uses LLMs to read natural language problems and generate programs as the intermediate reasoning steps. Coined, program-aided language models (PAL), it differs from chain-of-thought prompting in that instead of using free-form text to obtain solution it offloads the solution step to a programmatic runtime such as a Python interpreter.

Full example coming soon!
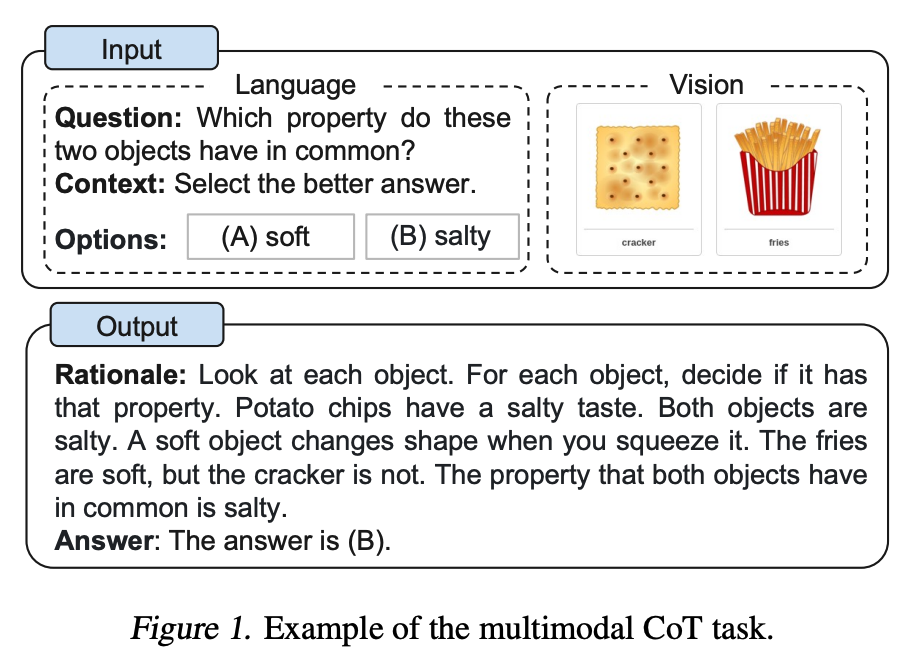
Multimodal CoT Prompting
Zhang et al. (2023) recently proposed a multimodal chain-of-thought prompting approach. Traditional CoT focuses on the language modality. In contrast, Multimodal CoT incorporates text and vision into a two-stage framework. The first step involves rationale generation based on multimodal information. This is followed by the second phase, answer inference, which leverages the informative generated rationales.
The multimodal CoT model (1B) outperforms GPT-3.5 on the ScienceQA benchmark.