19 KiB
Advanced Prompting
By this point, it should be obvious that it helps to improve prompts to get better results on different tasks. That’s the whole idea behind prompt engineering.
While those examples were fun, let’s cover a few concepts more formally before we jump into more advanced concepts.
Topics:
- Zero-shot Prompts
- Few-shot Prompts
- Chain-of-Thought Prompting
- Zero-shot CoT
- Self-Consistency
- Generate Knowledge Prompting
- Automatic Prompt Engineer
Few-Shot Prompts
Before jumping into more advanced concepts, let’s review an example where we use few-shot prompts.
Do you recall the previous example where we provided the following task:
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A: If we try this again, the model outputs the following:
Yes, the odd numbers in this group add up to 107, which is an even number.Again, this is not the correct response, which not only highlights the limitations of these systems but that there is a need for more advanced prompt engineering.
Let’s try to add some examples, to see if this improves the results.
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A: Output:
The answer is True.That didn’t work. It seems like basic standard prompting is not enough to get reliable responses for this type of reasoning problem. The example above provides basic information on the task, even with the examples. If you take a closer look at the task, it does involve more reasoning steps.
More recently, chain-of-thought (CoT) prompting has been popularized to address more complex arithmetic, commonsense, and symbolic reasoning tasks. So let’s talk about CoT next and see if we can solve the above task.
Following the findings from Min et al. (2022), here a few more tips about demonstrations/exemplars when doing few-shot:
- the label space and the distribution of the input text specified by the demonstrations are both key (regardless of whether the labels are correct for individual inputs).
- the format you use also plays a key role in performance; Even if you just use random labels, this is much better than no labels at all.
- additional results show that selecting random labels from a true distribution of labels (instead of a uniform distribution) also helps.
Let’s try out a few examples. Let’s first try an example with random labels (meaning the labels Negative and Positive are randomly assigned to the inputs):
Prompt:
This is awesome! // Negative
This is bad! // Positive
Wow that movie was rad! // Positive
What a horrible show! //Output:
NegativeWe still get the correct answer, even though the labels have been randomized. Note that we also kept the format, which helps too. In fact, with further experimentation it seems the newer GPT models we are experimenting with are becoming more robust to even random format. Example:
Prompt:
Positive This is awesome!
This is bad! Negative
Wow that movie was rad!
Positive
What a horrible show! --Output:
NegativeThere is no consistency in the format above but the model still predicted the correct label. We have to conduct more thorough analysis to confirm if this holds true for different and more complex tasks, including different variations of prompts.
Overall, it seems that providing examples is useful in some places. When zero-shot prompting and few-shot prompting are not sufficient, it might mean that the whatever was learned by the model isn’t enough to do well at the task. From here it is recommended to start thinking about fine-tuning your own models.
Chain-of-Thought Prompting
Introduced in Wei et al. (2022), chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. You can combine it with few-shot prompting to get better results on more complex tasks that require reasoning before responding.
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.Wow! We can see a perfect result when we provided the reasoning step. In fact, we can solve this task by providing even fewer examples, i.e., just one example seems enough:
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.Keep in mind that the authors claim that this is an emergent ability that arises with sufficiently large language models.
Zero-Shot CoT
One recent idea that came out more recently is the idea of zero-shot CoT (Kojima et al. 2022) that essentially involves adding “Let’s think step by step” to the original prompt. Let’s try a simple problem and see how the model performs:
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?Output:
11 applesThe answer is incorrect! Now Let’s try with the special prompt.
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to the neighbor and 2 to the repairman. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.Output:
First, you started with 10 apples.
You gave away 2 apples to the neighbor and 2 to the repairman, so you had 6 apples left.
Then you bought 5 more apples, so now you had 11 apples.
Finally, you ate 1 apple, so you would remain with 10 apples.It’s actually impressive that this simple prompt is effective at this task. This is particularly useful where you don’t have too many examples to use in the prompt.
Self-Consistency
Perhaps one of the more advanced techniques out there for prompt engineering is self-consistency. Proposed by Wang et al. (2022), self-consistency aims “to replace the naive greedy decoding used in chain-of-thought prompting”. The idea is to sample multiple, diverse reasoning paths through few-shot CoT, and use the generations to select the most consistent answer. This helps to boost the performance of CoT prompting on tasks involving arithmetic and commonsense reasoning.
Let’s try the following example for arithmetic reasoning:
Prompt:
When I was 6 my sister was half my age. Now
I’m 70 how old is my sister?Output:
35The output is obviously wrong! How may we improve this with self-consistency? Let’s try it out. We will use the few-shot exemplars from Wang et al. 2022 (Table 17):
Prompt:
Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done,
there will be 21 trees. How many trees did the grove workers plant today?
A: We start with 15 trees. Later we have 21 trees. The difference must be the number of trees they planted.
So, they must have planted 21 - 15 = 6 trees. The answer is 6.
Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?
A: There are 3 cars in the parking lot already. 2 more arrive. Now there are 3 + 2 = 5 cars. The answer is 5.
Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?
A: Leah had 32 chocolates and Leah’s sister had 42. That means there were originally 32 + 42 = 74
chocolates. 35 have been eaten. So in total they still have 74 - 35 = 39 chocolates. The answer is 39.
Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops
did Jason give to Denny?
A: Jason had 20 lollipops. Since he only has 12 now, he must have given the rest to Denny. The number of
lollipops he has given to Denny must have been 20 - 12 = 8 lollipops. The answer is 8.
Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does
he have now?
A: He has 5 toys. He got 2 from mom, so after that he has 5 + 2 = 7 toys. Then he got 2 more from dad, so
in total he has 7 + 2 = 9 toys. The answer is 9.
Q: There were nine computers in the server room. Five more computers were installed each day, from
monday to thursday. How many computers are now in the server room?
A: There are 4 days from monday to thursday. 5 computers were added each day. That means in total 4 * 5 =
20 computers were added. There were 9 computers in the beginning, so now there are 9 + 20 = 29 computers.
The answer is 29.
Q: Michael had 58 golf balls. On tuesday, he lost 23 golf balls. On wednesday, he lost 2 more. How many
golf balls did he have at the end of wednesday?
A: Michael initially had 58 balls. He lost 23 on Tuesday, so after that he has 58 - 23 = 35 balls. On
Wednesday he lost 2 more so now he has 35 - 2 = 33 balls. The answer is 33.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
A: She bought 5 bagels for $3 each. This means she spent 5
Q: When I was 6 my sister was half my age. Now I’m 70 how old is my sister?
A:Output 1:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70 - 3 = 67. The answer is 67.Output 2:
When the narrator was 6, his sister was half his age, which is 3. Now that the narrator is 70, his sister would be 70 - 3 = 67 years old. The answer is 67.Output 3:
When I was 6 my sister was half my age, so she was 3. Now I am 70, so she is 70/2 = 35. The answer is 35.Computing for the final answer involves a few steps (check out the paper for the details) but for the sake of simplicity, we can clearly see that there is already a majority answer emerging so that would essentially become the final answer.
Automatic Prompt Engineer (APE)
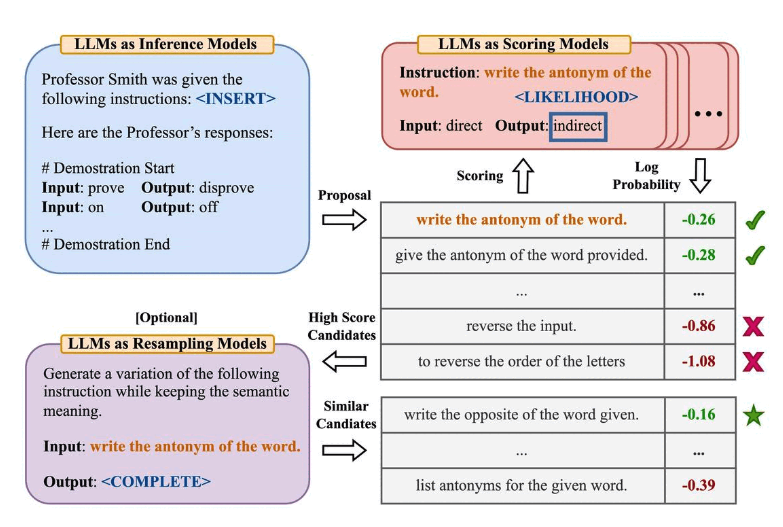
Zhou et al., (2022) propose automatic prompt engineer (APE) a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis addressed as a black-box optimization problem using LLMs to generate and search over candidate solutions.
The first step involves a large language model (as inference model) that is given output demonstrations to generate instruction candidates for a task. These candidate solution will guide the search procedure. The instructions are executed using a target model, and then the most appropriate instruction is selected based on computed evaluation scores.
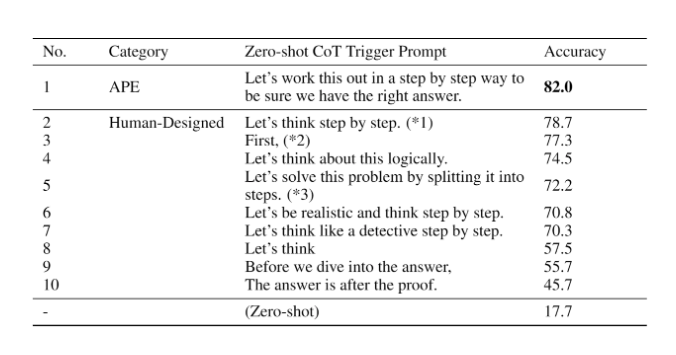
APE discovers a better zero-shot CoT prompt than the human engineered “Let’s think step by step” prompt from (Kojima et al., 2022).
The prompt “Let’s work this out it a step by step way to be sure we have the right answer.” elicits chain-of-though reasoning and improves performance on the MultiArith and GSM8K benchmarks:
This paper touches on an important topic related to prompt engineering which is this idea of automatically optimizing prompts. While we don’t go deep in this topic in this guide, here are few key papers if you are interested in the topic:
- AutoPrompt - proposes an approach to automatically create prompts for a diverse set of tasks based on gradient-guided search.
- Prefix Tuning - a lightweight alternative to fine-tuning that prepends a trainable continuous prefix for NLG tasks.
- Prompt Tuning - proposes a mechanism for learning soft prompts through back propagation.