14 KiB
데이터 처리: 비-관계형 데이터
](/python/data-science-for-beginners/media/commit/9f466a4e684ab81f787d4e49ea480dbc8a6c9958/sketchnotes/06-NoSQL.png) |
|---|
| 데이터 처리: NoSQL 데이터 - Sketchnote by [@nitya](https://twitter.com/nitya) |
강의 전 퀴즈
데이터는 관계형 데이터베이스에만 국한되지 않습니다. 이 과정을 통해 비-관계형 데이터에 초점을 맞춰 스프레드시트와 NoSQL의 기초에 대해 설명하겠습니다.
스프레드시트
스프레드시트는 설정 및 시작에 필요한 작업량이 적기 때문에 데이터를 저장하거나 탐색하는 일반적인 방법입니다. 이 과정에서는 공식 및 함수뿐만 아니라 스프레드시트의 기본 구성요소에 대해 알아보겠습니다. 예시들은 Microsoft Excel에서 다룰 것이며, 대부분의 다른 스프레드시트 소프트웨어 또한 유사한 이름과 단계들을 가지고 있습니다.

스프레드시트는 하나의 파일이며, 컴퓨터, 장치, 클라우드 기반 파일 시스템에서 접근할 수 있습니다. 소프트웨어 자체로써 브라우저 기반이거나 컴퓨터나 앱에서 다운로드해야 하는 응용 프로그램일 수도 있습니다. 엑셀에서 이러한 파일은 워크북이라고 정의되며, 이 과정의 나머지 부분에서 다시 설명하도록 하겠습니다.
워크북은 하나 이상의 워크시트가 포함되며, 각 워크시트에는 탭으로 레이블이 지정됩니다. 워크시트에는 셀이라 불리는 사각형이 있고, 실제 데이터가 여기에 들어가게 됩니다. 셀은 행과 열의 교차하며 열에는 알파벳 문자의 레이블, 행에는 숫자 레이블이 지정됩니다. 일부 스프레드시트는 처음 몇 행에 셀의 데이터를 설명하는 머릿글이 위치할 수도 있습니다.
엑셀 워크북의 기본 요소를 사용하며 스프레드시트의 몇가지 추가적인 기능을 살펴보기 위해서, 재고를 다루는 마이크로소프트 템플릿에서 제공하는 몇 가지 예제를 사용하겠습니다.
재고 관리
“재고 예시”라는 스프레드시트 파일은 세 개의 워크시트를 가지고 있는 재고 목록의 형식화된 스프레드시트입니다. 탭에는 “재고 목록”, “선택한 재고 목록”, “Bin 조회” 레이블을 가지고 있습니다. 재고 목록 워크시트의 4행은 각 셀의 값을 설명하는 머리글입니다.
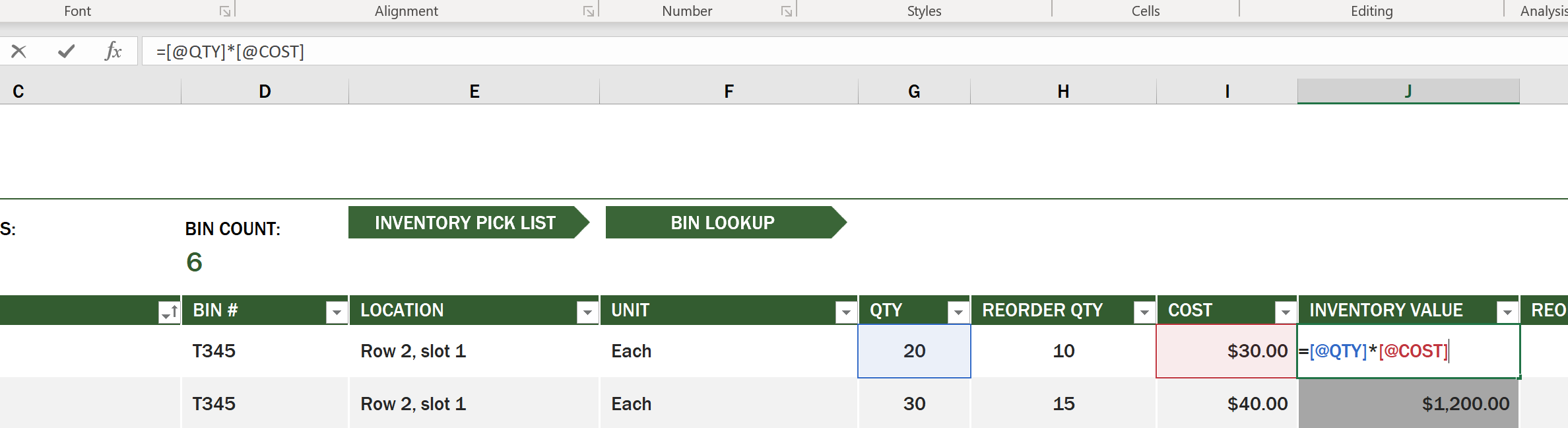
위의 예시 중 어떤 셀은 값을 생성하기 위해 다른 셀의 값에 의존하기도 합니다. 재고 목록 스프레드시트는 재고에 대한 단가는 가지고 있지만, 만약 우리가 재고의 전체적인 비용을 알아야 한다면 어떻게 할까? 이 예에서 공식 셀 데이터에 대해 계산을 수행하고 재고 비용을 계산하는 데 사용됩니다. 이 스프레드시트는 재고 비용 열의 공식을 사용해 QTY 헤더에 따른 수량과 COST 헤더에 따른 단가를 곱해 각 항목의 값을 계산했습니다. 셀을 두 번 클릭하거나 강조 표시하면 공식이 표시됩니다. 공식은 등호 다음에 계산 또는 연산으로 시작합니다.
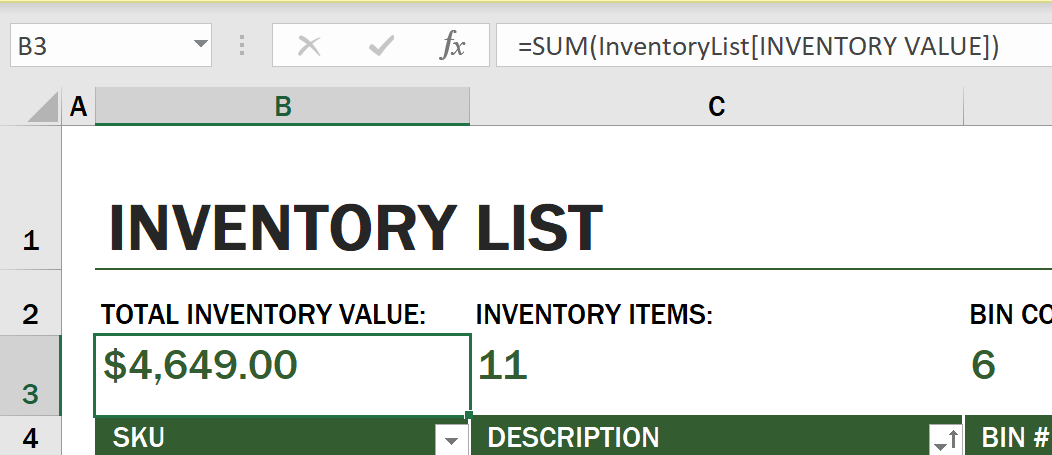
우리는 재고 비용의 모든 값을 더한 총 합계를 구하기 위해 다른 공식을 사용할 수도 있습니다. 총 합계를 계산하기 위해 각각의 셀을 추가해 계산할 수도 있지만, 이것은 너무 지루한 작업입니다. 이 같은 문제를 해결하기 위해 엑셀은 함수, 또는 셀 값에 대한 계산을 수행하기 위한 사전에 정의된 공식을 가지고 있습니다. 함수는 이러한 계산을 수행하는 데 필요한 값인 인수가 필요합니다. 함수에 둘 이상의 인수가 필요한 경우, 인수가 특정 순서로 나열되지 않는다면 올바른 값이 도출되지 않을 수 있습니다. 이 예제에서는 SUM 함수를 사용하겠습니다. 재고 값들을 인수로 사용해, 3행 B열(또는 B3)에 나열된 합계를 추가합니다.
NoSQL
NoSQL은 비관계적 데이터를 저장하는 다양한 방법을 포괄적으로 지칭하는 용어이며, “비SQL”, “비-관계적” 또는 “SQL의 확장”으로 해석될 수 있다. 이러한 유형의 데이터베이스 시스템은 4가지 유형으로 분류할 수 있습니다.
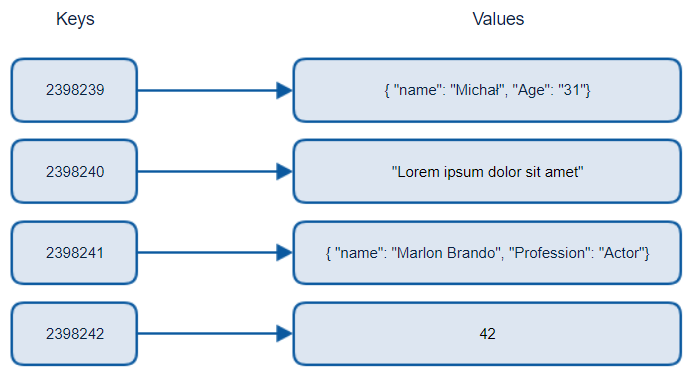 > 출처: Michał Białecki 블로그
> 출처: Michał Białecki 블로그
키-값 데이터베이스는 값과 연결된 고유 식별자인 고유 키를 쌍으로 구성합니다. 이러한 쌍들은 해시 함수를 사용하여 해시 테이블에 저장됩니다.
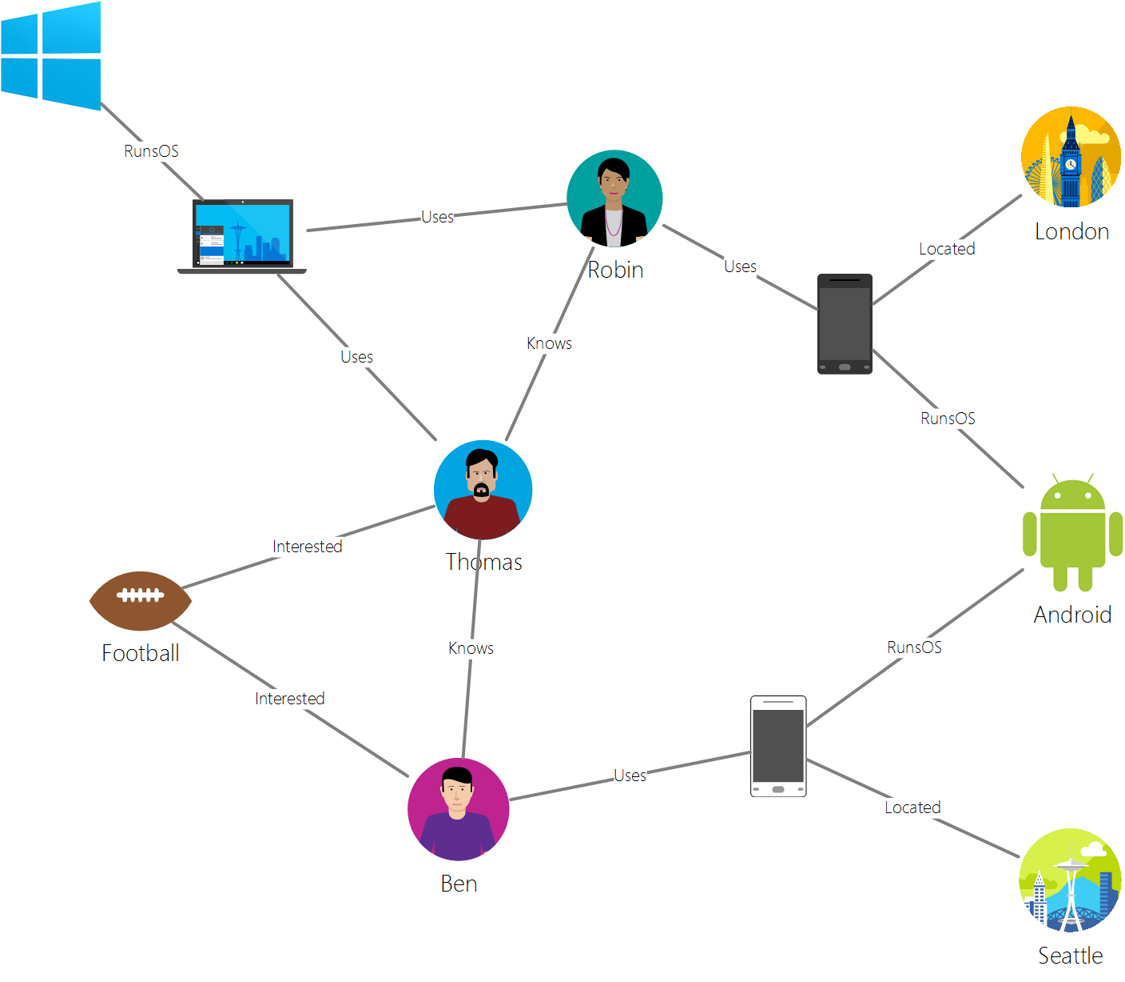 > 출처: Microsoft
> 출처: Microsoft
그래프 데이터베이스는 데이터의 관계를 설명하고 노드(node)와 엣지(edge)의 집합으로 표현됩니다. 노드는 학생 또는 은행 명세서처럼 실제 세계에 존재하는 엔티티를 나타냅니다. 엣지는 두 엔티티간의 관계를 나타냅니다. 각 노드와 가장자리는 각각에 대한 추가 정보를 제공하는 속성을 가지고 있습니다.

컬럼 기반 데이터 스토어는 데이터를 관계형 데이터 구조처럼 열과 행으로 구성하지만, 각 열은 컬럼패밀리(column family)라 불리는 그룹으로 나뉘며, 한 컬럼 아래의 모든 데이터가 관련되 하나의 단위로 검색 및 변경할 수 있습니다.
Azure Cosmos DB를 사용한 문서 데이터 저장소
문서 데이터 저장소는 키 값 데이터 저장소의 개념을 기반으로 하며, 일련의 필드와 객체로 구성됩니다. 이 섹션에서는 Cosmos DB 에뮬레이터를 사용하여 문서 데이터베이스를 살펴봅니다.
Cosmos DB 데이터베이스는 “Not Only SQL”의 정의에 부합하며, 여기서 Cosmos DB의 문서 데이터베이스는 SQL에 의존하여 데이터를 쿼리합니다. SQL에 대한 이전 과정에서는 언어의 기본 사항에 대해 설명하며 여기서 동일한 쿼리 중 일부를 문서 데이터베이스에 적용할 수 있습니다. 우리는 컴퓨터에서 로컬로 문서 데이터베이스를 만들고 탐색할 수 있는 Cosmos DB 에뮬레이터를 사용할 것입니다. 에뮬레이터에 관해서는 이곳에서 더 자세히 알아보세요.
문서는 필드 및 오브젝트 값의 집합으로, 여기서 필드는 오브젝트 값이 나타내는 것을 설명합니다. 아래는 문서의 예시입니다.
{
"firstname": "Eva",
"age": 44,
"id": "8c74a315-aebf-4a16-bb38-2430a9896ce5",
"_rid": "bHwDAPQz8s0BAAAAAAAAAA==",
"_self": "dbs/bHwDAA==/colls/bHwDAPQz8s0=/docs/bHwDAPQz8s0BAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f95-010a691e01d7\"",
"_attachments": "attachments/",
"_ts": 1630544034
}이 문서의 관심 필드는 firstname, id, 그리고 age 입니다. 밑줄이 있는 나머지 필드는 Cosmos DB에서 생성되었습니다.
Cosmos DB 에뮬레이터를 이용한 데이터 탐색
당신은 이곳에서 윈도우 전용 에뮬레이터를 다운로드하여 설치할 수 있습니다. macOS 및 Linux용 에뮬레이터를 실행하는 방법은 이 설명서를 참조하세요.
에뮬레이터는 탐색기 보기를 통해 문서를 탐색할 수 있는 브라우저 창을 실행합니다.
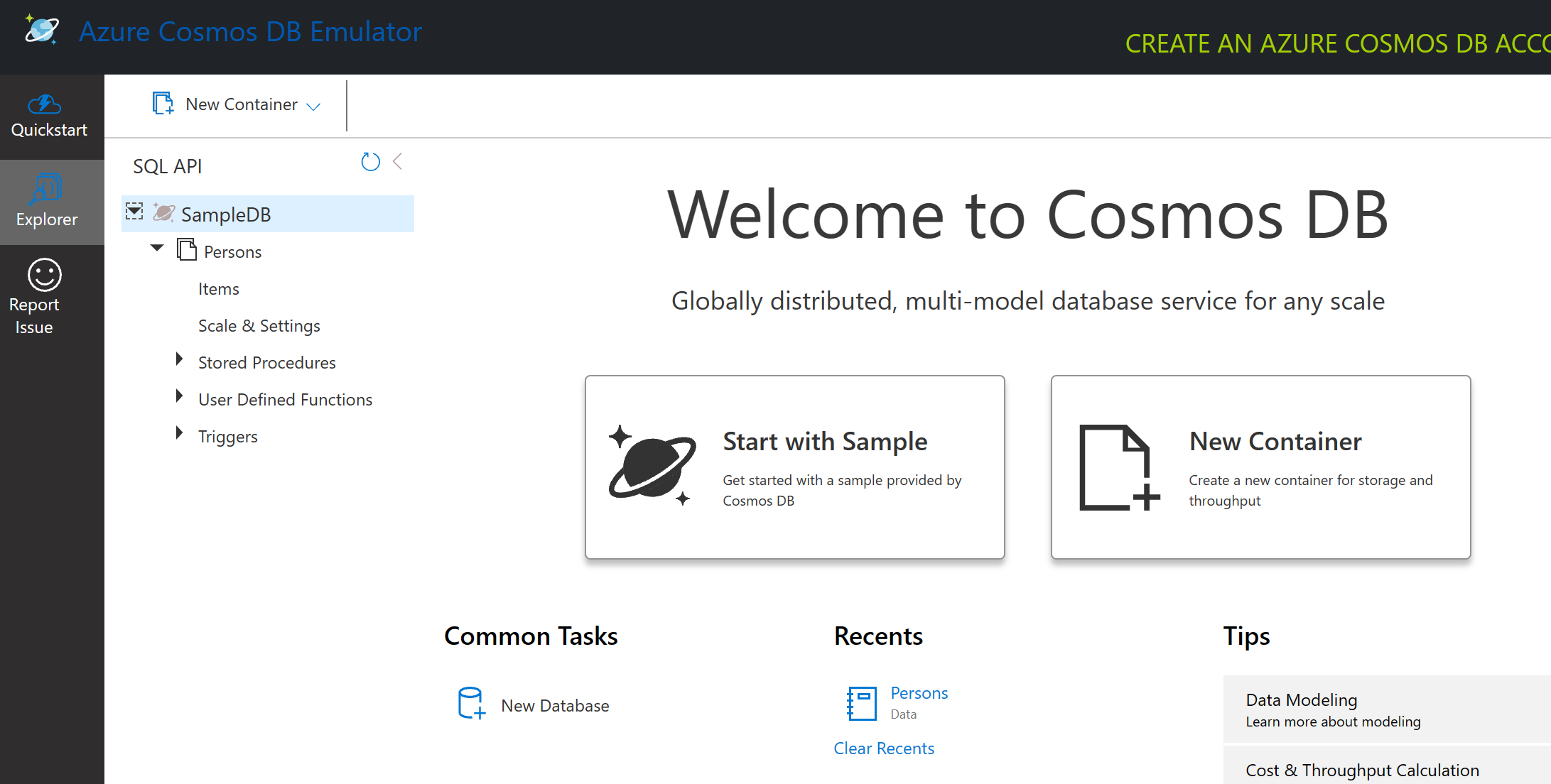
다음은 “샘플부터 시작(Start with Sample)”을 클릭하여 샘플DB(SampleDB)라고 불리는 샘플 데이터베이스를 생성합니다. 화살표를 클릭하여 샘플 DB를 확장하게 되면, 컨테이너 안에 있는 문서인 항목들을 모아둔 사람이라는 컨테이너가 있습니다. 당신은 이제 항목 아래에 있는 4개의 개별문서들을 탐색할 수 있습니다.
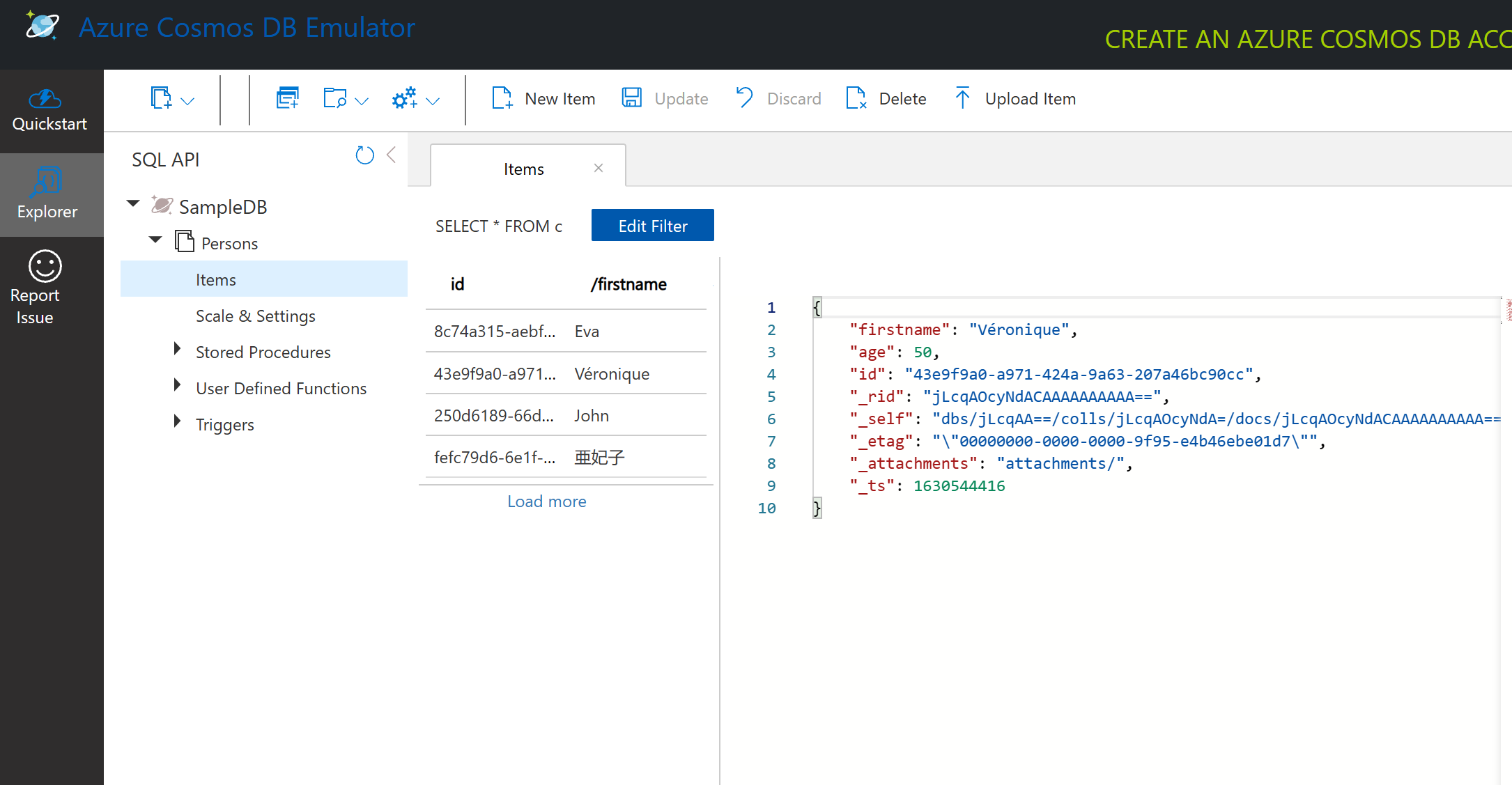
Cosmos DB 에뮬레이터를 사용한 문서 데이터 쿼리
우리는 또한 새로운 SQL Query 버튼(왼쪽에서 2번째 버튼)을 클릭하여 샘플 데이터를 조회할 수 있습니다.
SELECT * FROM c 는 컨테이너에 있는 모든 문서를 반환합니다. WHERE 절을 추가하고 40세 이하의 모든 사람을 찾아봅시다!
SELECT * FROM c where c.age < 40

이 쿼리는 나이에 대한 값이 40보다 작은 두 개의 문서를 반환합니다.
JSON 과 문서들
만약 당신이 JavaScript Object Notation (JSON)에 익숙한 경우 문서가 JSON과 유사하다는 것을 알 수 있습니다. 이 디렉토리에는 항목 업로드 버튼을 통해 에뮬레이터의 사용자 컨테이너에 업로드할 수 있는 더 많은 데이터가 포함된 PersonData.json 파일이 있습니다.
대부분의 경우 JSON 데이터를 반환하는 API는 문서 데이터 베이스에 직접 전송 및 저장할 수 있습니다. 아래는 트위터 API를 사용하여 검색된 마이크로소프트 트위터 계정의 트윗을 나타낸 문서이며 Cosmos DB에 삽입되었습니다.
{
"created_at": "2021-08-31T19:03:01.000Z",
"id": "1432780985872142341",
"text": "Blank slate. Like this tweet if you’ve ever painted in Microsoft Paint before. https://t.co/cFeEs8eOPK",
"_rid": "dhAmAIUsA4oHAAAAAAAAAA==",
"_self": "dbs/dhAmAA==/colls/dhAmAIUsA4o=/docs/dhAmAIUsA4oHAAAAAAAAAA==/",
"_etag": "\"00000000-0000-0000-9f84-a0958ad901d7\"",
"_attachments": "attachments/",
"_ts": 1630537000이 문서의 관심 필드는 created_at, id, 그리고 text 입니다.
🚀 과제
샘플 DB 데이터베이스에 업로드할 수 있는 TwitterData.json 파일이 있습니다. 별도의 컨테이너에 추가하는 것을 추천합니다. 이 작업은 다음에 따라 수행할 수 있습니다.:
- 오른쪽 상단에 있는 새 컨테이너 버튼을 클릭합니다.
- 컨테이너에 대한 컨테이너 id 를 작성하는 기존 데이터베이스(Sample DB)를 선택합니다.
- 파티션 키를
/id로 설정합니다. - OK(확인)를 클릭합니다.(이 보기의 나머지 정보는 컴퓨터에서 로컬로 실행되는 작은 데이터 집합이므로 무시할 수 있습니다.)
- 새 컨테이너를 열고
항목업로드버튼으로 트위터 데이터 파일을 업로드합니다.
텍스트 필드에 Microsoft가 있는 문서를 찾기 위해 몇 가지 쿼리를 실행해 보십시오. 힌트: LIKE 키워드를 사용해 보십시오.
강의 후 퀴즈
리뷰 & 복습
이 과정에서는 다루지 않는 일부 추가 형식 및 기능이 이 스프레드쉬트에 추가되었습니다. 마이크로 소프트는 흥미를 가질만한 엑셀에 대한 많은 영상과 문서들을 가지고 있습니다.
이 아키텍처 문서에는 여러 유형의 비관계형 데이터의 특성이 자세히 나와 있습니다: 비-관계형 데이터와 NoSQL
Cosmos DB는 클라우드 기반 비관계형 데이터베이스로, 이 과정에서 언급한 다양한 NoSQL 유형도 저장할 수 있습니다. Cosmos DB Microsoft 학습 모듈에서 이러한 유형에 대해 자세히 알아보세요.